WeChat ID
aaronpk_tv
#IndieAuth
-
#IndieAuth is a pretty neat thing, and as I'm already a big #RSS user (have been since they were in general use, just never dropped them) I guess it'd be cool to have what amounts to a way to log into various sites that I don't feel called to make single accounts for and certainly don't feel like giving access to my Gmail or Facebook.
Trouble is, I have very few places where I can put a ref="me" and a lot of the people I know don't either. Many sites don't let us edit the style sheet.
-
I've set up #IndieAuth on my personal site. Now on the two sites that support it I can log in using myself as an IDP.
-
 It's already been a year since #IndieAuth was published as a @W3C Note! Support from new services and some new plugins as well! https://aaronparecki.com/2019/01/23/22/indieauth
It's already been a year since #IndieAuth was published as a @W3C Note! Support from new services and some new plugins as well! https://aaronparecki.com/2019/01/23/22/indieauth -
IndieAuth: One Year Later
 It's already been a year since IndieAuth was published as a W3C Note! A lot has happened in that time! There's been several new plugins and services launch support for IndieAuth, and it's even made appearances at several events around the world!continue reading...
It's already been a year since IndieAuth was published as a W3C Note! A lot has happened in that time! There's been several new plugins and services launch support for IndieAuth, and it's even made appearances at several events around the world!continue reading... -
This morning I gave a brief talk about IndieAuth at the @W3C Strong Authentication and Identity workshop. I just finished transcribing the recording and published the slides and video! https://www.youtube.com/watch?v=EeCNlB7v08I
-
My post on the Mozilla Hacks blog was just published! "Identity for the Decentralized Web with IndieAuth" https://hacks.mozilla.org/2018/10/dweb-identity-for-the-decentralized-web-with-indieauth/
If you're at #iiw today, I'll be at demo hour showing how this works! -
We will be talking about 'The Many Flavors of OAuth' at @APIdaysGlobal San Francisco about #oauth2 and briefly covering identity layers #openidconnect #oidc and #IndieAuth. We have a few tickets to giveaway. Please register with code 'Soonhin' at https://www.apidays.co/sanfrancisco. See you!
-
Will be talking about 'The Many Flavors of OAuth' at https://www.apidays.co/sanfrancisco including brief overview of identity layers #openidconnect #oidc, and #IndieAuth. Use code 'Soonhin' to get free tix. @aaronpk thanks for https://aaronparecki.com/2018/07/07/7/oauth-for-the-open-web.
-
Pretty great to see a new self-hosted IndieAuth server! Congrats @nilshauk, and great project name! https://twitter.com/nilshauk/status/1017485223716630528
-
By golly, it's working. Here's me using Cellar Door to login to #IndieWeb's #IndieAuth page to add my implementation to the list of available implementations. ☺️ https://indieweb.org/IndieAuth#Implementations
-
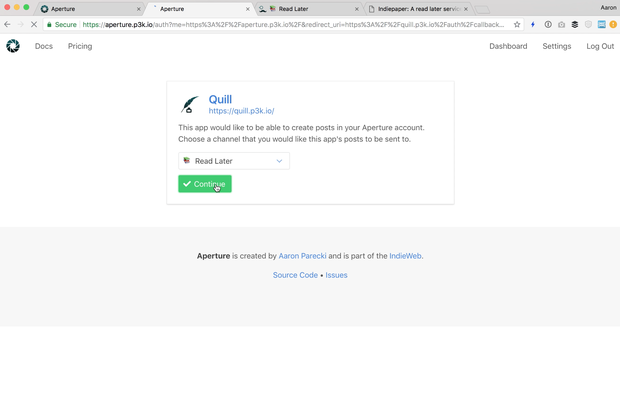
I just implemented an IndieAuth server for Aperture, which sounds crazy but it's actually pretty cool. Now you can log in to apps like https://indiepaper.io and they can post content directly into a private channel!
If you have an Aperture account, try logging in to Quill using https://aperture.p3k.io as your URL. Here's a little demo of it in action! -
OAuth for the Open Web
 OAuth has become the de facto standard for authorization and authentication on the web. Nearly every company with an API used by third party developers has implemented OAuth to enable people to build apps on top of it.continue reading...
OAuth has become the de facto standard for authorization and authentication on the web. Nearly every company with an API used by third party developers has implemented OAuth to enable people to build apps on top of it.continue reading... -
tl;dr The more I think about it, the more I think this parameter enables a use case that isn't really necessary. The
meparameter in the code exchange step specifically allows for a token endpoint to be detached from both the Micropub endpoint and the authorization endpoint.Full details below.
The different use cases that are all supported right now:
Integrated Micropub/Token/Authorization Endpoints
This is the simplest case in terms of architecture, but the most amount of work for a developer. In this case, someone writes all three parts of the system. Since they are part of the same system, the mechanism by which the token endpoint validates authorization codes does not need to be standardized, it's all internal.
Both my website and the Wordpress IndieAuth plugin fall under this case.
Authorization Endpoint Service, Built-In Token and Micropub Endpoints
In this case, someone is building a CMS that includes a Micropub endpoint as well as a token endpoint. However, they want to speed up their development, so they use an authorization endpoint service such as indieauth.com.
The client sends the auth code to the token endpoint, and since the token endpoint is part of the CMS, it already knows the only place it can go to validate the auth code is the authorization endpoint service that it's configured to use. Therefore there is no need for the
meparameter, which normally tells the token endpoint where to go to verify the auth code.Authorization Endpoint and Token Endpoint Service
Specifically this case is where a service provides both an authorization endpoint and token endpoint. This is the quickest path to building a Micropub endpoint, since all you need to do is build out the Micropub endpoint itself, and when any requests come in with a token, the endpoint goes and checks whether the token is valid by testing it against the token endpoint service.
This is a very common case with peoples' individual websites, as it offloads the development and maintenance of the security bits to a service. I provide these as a service at indieauth.com and tokens.indieauth.com.
The interesting thing though is that when a single service provides both, there is also no need for the
meparameter at the code exchange step, since the token endpoint already knows where it needs to verify the authorization code since the code was issued by the same system.Separate Authorization Endpoint and Token Endpoint Services
The only case where the
meis needed is when the authorization endpoint and token endpoint are both used as services and they are separate services. Imagine a standalone token endpoint service: the job of this service is to verify authorization codes and issue access tokens, and later verify access tokens. In this situation, a request comes in with an unknown authorization code and it needs to verify it. Since it was not part of the system that issued the code, it needs to know how to verify it. Right now, this is enabled because this request also includes themeparameter, so the token endpoint goes and looks up the user's authorization endpoint and verifies the code there.The thing I'm realizing though is that this is really quite an edge case, and one that I don't think is actually very important. Typically someone who is building a Micropub endpoint themselves will first start by using an authorization/token endpoint service, and there is no benefit to them if those are two separate services. In fact it's probably easier if they are just part of the same system since it's less moving parts to think about at this stage.
Later, that person can decide they want to take over issuing tokens, but still don't want to build out the UI of an authorization service. At this point, they fall under the second use case above. They build out a token endpoint into their software, and since they're using the authorization endpoint service they know where to verify authorization codes.
On the other end of the spectrum, you have people who build the whole thing out themselves, like my website and the Wordpress plugin. In these cases the
meis completely irrelevant in the code exchange step.The particular situation that the
meenables is using a separate service for the authorization and token endpoints, and I can't think of a case where that is actually important. -
What we really need is federated authentication, but that doesn't exist yet.
This sounds like a great use case for IndieAuth. w3.org/TR/indieauth
IndieAuth is an OAuth 2.0 extension, which avoids the centralized problems with existing OAuth solutions by using DNS for "registration" of client IDs and user IDs. Every user account is identified by a URL (for Gitea this could be your Gitea user page), and client IDs are also URLs (would be the Gitea instance home page in this case.)
To log in to your Gitea instance, I would enter my own Gitea profile URL. Your instance would then do discovery on my URL to find where to send me to authorize the login on my own OAuth server (my Gitea server), which would then send me back to your Gitea where it would be able to verify the authorization code against my Gitea instance.
I'd be happy to walk through this in more detail if you're interested!
-
Just finished beta support for email and PGP auth on https://indielogin.com! Please give it a try and let me know if you find any bugs! Here are the setup docs: https://indielogin.com/setup
This means it's now feature complete with https://indieauth.com, so I can now start switching over my apps to use it. With any luck I'll be able to switch the https://indieweb.org wiki to it before IndieWeb Summit!

{kind=link}