
WeChat ID
aaronpk_tv
#IndieAuth
-
 Well this is moving quickly! You can now spin up FedCM on your own website and log in to https://webmention.io thanks to this open source project from Sam Goto! This is so much better than having to type out your website or even email address when logging in! Full instructions here:
Well this is moving quickly! You can now spin up FedCM on your own website and log in to https://webmention.io thanks to this open source project from Sam Goto! This is so much better than having to type out your website or even email address when logging in! Full instructions here:
https://github.com/fedidcg/FedCM/issues/240#issuecomment-2118606184 -
This weekend I built a prototype of using FedCM for IndieAuth! This gets rid of the need to enter your domain when logging in to websites using IndieAuth! Demo video and notes here: https://aaronparecki.com/2024/05/12/3/fedcm-for-indieauth
-
FedCM for IndieAuth
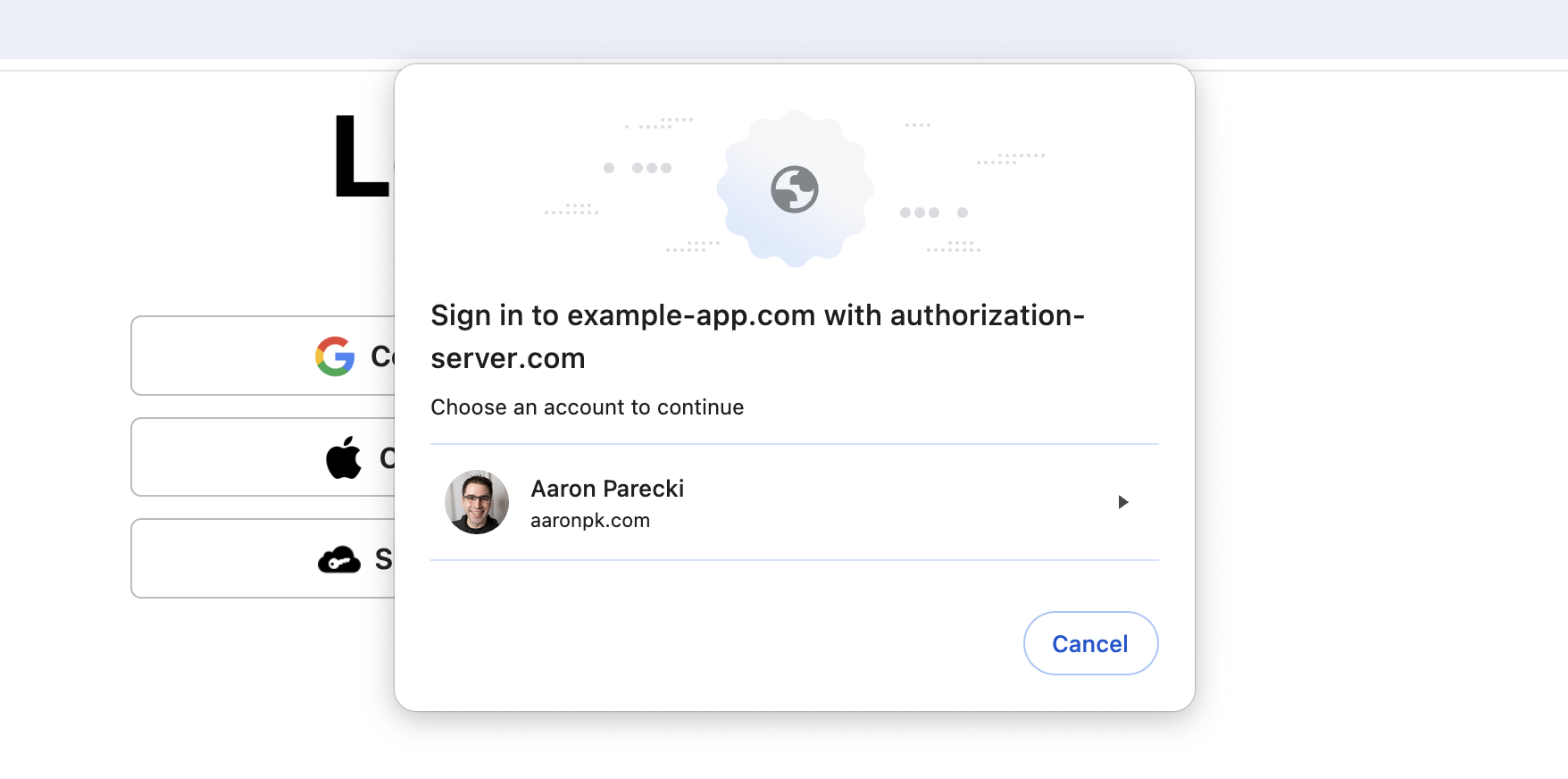 IndieWebCamp Düsseldorf took place this weekend, and I was inspired to work on a quick hack for demo day to show off a new feature I've been working on for IndieAuth.continue reading...
IndieWebCamp Düsseldorf took place this weekend, and I was inspired to work on a quick hack for demo day to show off a new feature I've been working on for IndieAuth.continue reading... -
OAuth Support in Bluesky and AT Protocol
 Bluesky, a new social media platform and AT Protocol, is unsurprisingly running up against the same challenges and limitations that Flickr, Twitter and many other social media platforms faced in the 2000s: passwords!continue reading...
Bluesky, a new social media platform and AT Protocol, is unsurprisingly running up against the same challenges and limitations that Flickr, Twitter and many other social media platforms faced in the 2000s: passwords!continue reading... -
New #indieweb libraries: taproot/micropub-adapter and taproot/indieauth!
Finally put the finishing touches on these two closely-related libraries, which make it quick and easy to add Micropub and IndieAuth support to any PHP app which uses PSR-7.
Feedback appreciated, either as replies, GH issues, or at indieweb.org/discuss
-
How to Sign Users In with IndieAuth
This post will show you step by step how you can let people log in to your website with their own IndieAuth website so you don't need to worry about user accounts or passwords.continue reading... -
Tonight I've been investigating a few things for my #Postman API Hack and I've found that Postman's OAuth2 support is pretty awesome - it works very nicely with #Indieauth which is an important part of my hack 😉 I'm also pretty happy with what I'm planning on doing - hoping to get some good progress with the hack itself this weekend, too!
-
Just to throw this out there, IndieAuth is a very small addition to OAuth 2.0 which adds identity into the system in a much lighter weight way than OpenID Connect. Mastodon could easily add this extension to return the user ID of the user who just authenticated. The login form on OwnCast would ask the user to enter their server name, and do discovery on the server to send the user there to log in.
I did a talk about how Mastodon/ActivityPub apps can use IndieAuth to accomplish this kind of thing. The video is available -- of course -- on my website: https://aaronparecki.com/2020/09/22/25/activitypub-oauth-2-1
-
IndieAuth Spec Updates 2020
This year, the IndieWeb community has been making progress on iterating and evolving the IndieAuth protocol. IndieAuth is an extension of OAuth 2.0 that enables it to work with personal websites and in a decentralized environment.continue reading... -
ActivityPub and OAuth 2.1 Live Q&A
This is the live Q&A session for my talk at ActivityPub Conference 2020. Watch the talk video here!continue reading...
