WeChat ID
aaronpk_tv
#100daysofcode
-
I really appreciate everyone's kind, funny & encouraging words on my single div iPad. Thank you so much 💛
Feel free to check out the code here on 📱 or 💻! @CodePen 👉 https://codepen.io/anniebombanie/pen/pojmNzN
(Inspired by @lynnandtonic)
#100DaysOfCode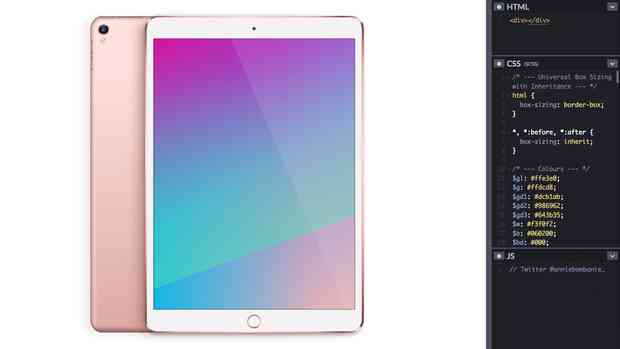
-
Inspired by @NikkitaFTW, I’ve decided to embark on a new adventure...
#100DaysOfDumbShit
🦄💫🤷♀️💩💖👻🥳
It’s like #100DaysOfCode but where you only build dumb shit 💁♀️ I won’t post every day, but when I have something dumb and (mostly) finished - I promise to share 💅🏼 -
Day 22: XRay Ready for Deployment #100DaysOfIndieWeb
Today I made a few changes to XRay to make it easier to deploy in more kinds of environments. I also removed a bunch of CSS/JS dependencies and simplified the UI a bit.continue reading... -
Day 21: Twitter Support for XRay #100DaysOfIndieWeb
Continuing yesterday's work, today I added support for parsing Twitter URLs to XRay.There were a couple tricks to make this work. I wanted to make sure that Tweets are always expanded to include the most data possible, and also wanted to avoid needing to make a bunch of HTTP requests. Scraping from the twitter.com website wasn't an option, since some of the data isn't available or would require additional HTTP calls to fetch. (For example I would have to fetch every t.co URL to expand them.) So I set to work using the Twitter API to fetch the tweets.continue reading... -
Day 20: Instagram Support for XRay #100DaysOfIndieWeb
XRay is my service that parses web pages and extracts information from them. Right now I mostly use it to parse comments, but now that I've been adding support for reposts, it's used there as well.Today I added support for XRay to extract data from Instagram URLs!This means anything that uses XRay will now return structured data when given an Instagram URL, just like how it parses h-entry and other Microformats. Unfortunately, Instagram does not provide timezone data for the published date, only a Unix timestamp. So if the photo is tagged at a location, then XRay will look up the appropriate timezone for that location and adjust the timezone of the published date accordingly!Here's what the parsed JSON looks like for this photo. Note that the timezone is set to East Coast because this photo was taken at MIT.{ "data":{ "type":"entry", "url":"https://www.instagram.com/p/BM4rGs-lApG/", "author":{ "type":"card", "name":"Aaron Parecki", "url":"http://aaronparecki.com/", "photo":"https://scontent.cdninstagram.com/t51.2885-19/s320x320/14240576_268350536897085_1129715662_a.jpg" }, "content":{ "text":"Here again" }, "photo":[ "https://scontent.cdninstagram.com/t51.2885-15/e35/14269001_1162908790471145_6084871298582839296_n.jpg?ig_cache_key=MTM4NTA0NjQ2MjAyNzc5NTAxNA%3D%3D.2" ], "location":[ "https://www.instagram.com/explore/locations/206258876/" ], "published":"2016-11-16T16:07:06-05:00" }, "refs":{ "https://www.instagram.com/explore/locations/206258876/":{ "type":"card", "name":"Massachusetts Institute of Technology (MIT)", "url":"https://www.instagram.com/explore/locations/206258876/", "latitude":42.360011410484, "longitude":-71.091869836761 } }}In addition to my website using this for reposts and comments, when I paste that URL into IRC, Loqi uses XRay to expand it and provide a little text preview.continue reading... -
Day 17: Documentation for Quill #100DaysOfIndieWeb
Quill started out as a sample Micropub client with a lot of useful debugging information. As it's grown, I've been slowly adding more posting interfaces to Quill, and tweaking them to look less like a debugging tool and more like a real app. Instead, micropub.rocks has taken over as a more detailed debugging utility for building a Micropub endpoint, so I can now optimize Quill for being more user-friendly and less developer-focused. At IndieWebCamp Germany in 2015, I added a rich editor to Quill, inspired by the clean Medium interface. You can even use the Quill rich editor without being logged in! It will save the post to your browser's localstorage as a draft, and let you post it after you log in. I wanted to make an interface that anybody would feel comfortable writing in, and be able to show it to people without them first logging in, as an introduction to what it might look like to have nice writing applications that aren't tied to a specific backend like Medium.In order to help people get started with Quill, today I wrote some more documentation for it!When you're logged out and click the "publish" button, it prompts you to log in and links out to the documentation home page.continue reading... -
Day 16: Improved Comments Display for p3k #100DaysOfIndieWeb
Today I started autolinking the text in comments on my website, and made a couple other minor improvements to how they look.Previously, links, @-names and hashtags were rendered as plaintext, so comments weren't clickable.continue reading... -
Day 15: Tags, Slug and Post Status for Quill #100DaysOfIndieWeb
I've been using Quill to write all these #100DaysOfIndieWeb posts, which is a great way to find the pain points in the interface. After having written 14 articles in the last 14 days, the main thing I want to be able to do is start an article here in the Quill editor, save it as a draft to my website, then open up the raw HTML to make fine-grained edits, and only after I'm done, actually publish it.continue reading... -
Day 14: Posting to my Website from Alexa #100DaysOfIndieWeb
If you know me, you probably know that I log everything I eat and drink and post it to my website. A couple years ago, I wrote a small Pebble app that allowed me to quickly post common food and drink from my watch! Coincidentally around the time Pebble announced that FitBit had acquired their assets, my Pebble stopped working completely. This meant I no longer had a quick way to log food, and have to pull out my phone again to make log entries.This afternoon, Tantek suggested that I use my Amazon Alexa to post food and drink to my website instead! Of course this will only work when I'm at home, but it turns out that I'm home a lot of the time I'm eating and drinking. I also eat tacos every day, so it'd be great not to have to get out my phone during breakfast.So today, I launched Alexa integration for Teacup, the app I use to track my food.This was quite a challenging project given all the moving parts involved. I started by defining the voice interface I wanted to use. Interaction ModelVoice interactions for Alexa apps have to follow a pretty strict structure. Alexa doesn't support interpreting fully unstructured text, so app developers have to define patterns that Alexa can match on. Invoking any Alexa app involves first speaking the trigger word, followed by a keyword such as "ask" or "tell" followed by the app name, and then the pattern of text the app wants to match. So for Teacup, this results in speaking sentences such as:"Alexa, tell Teacup I drank coffee""Alexa, tell Teacup I ate tacos"This gets turned into what Amazon calls the "Interaction Model", and is a list of "slots" along with corresponding keywords for each slot, as well as writing out some sample sentences.LIST_OF_ACTIONS = ate | drankLIST_OF_FOOD = Coffee | Cocktail | Beer | Tacos | Mac and Cheese | ...Sample utterances:"I {Action} {Food}""I {Action} a {Food}"It isn't clear to me whether the list of keywords I provided is the complete set, because while I was testing, it managed to post the word "on" for the food, which is not in my list.AuthenticationThe next challenge was linking user accounts between Amazon users and Teacup users. Amazon provides great documentation on this, and thankfully it's all based on OAuth 2.0 rather than having made up some other model themselves. Essentially, the Amazon Alexa app on your phone acts as an OAuth 2.0 client, and you have to build an OAuth 2.0 server into your app that it works against. This is a pretty clever solution actually. Luckily, I'm pretty familiar with OAuth 2.0, so I was able to build this out pretty quickly.One thing struck me about Amazon's recommendations about building OAuth support in your app. They say that they'll launch your authorization URL from inside the iOS app, which is a known antipattern for apps in general. In Amazon's docs, it says "The user logs in using their normal credentials for your site." This is a really bad idea. You never want to train your users to enter their passwords into random apps. This is the whole reason we have OAuth in the first place!continue reading... -
Day 13: Curved Lines for Atlas Static Maps #100DaysOfIndieWeb
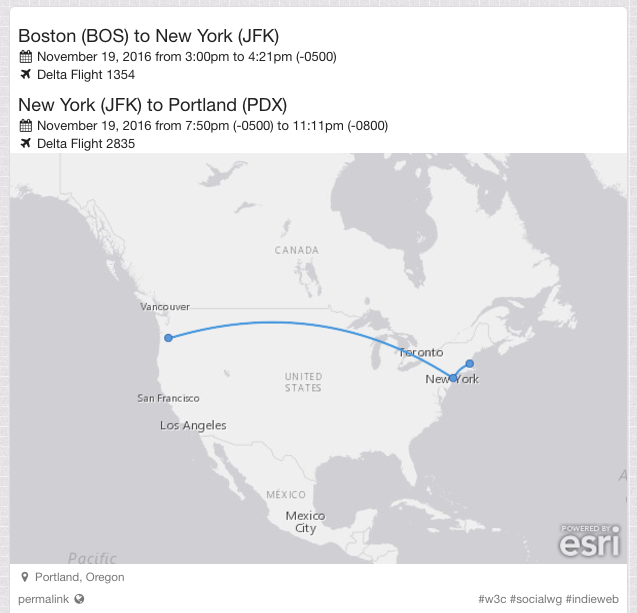 Yesterday, Amy was asking if there was a library for drawing curved lines between two points on a map. She wants to use this for her travel posts, which say for example "Tokyo to Boston". We noticed that Facebook draws curved lines when they show a planned trip. Martijn was able to figure out how to reproduce this on Facebook consistently. You have to start by creating a "checkin" post, then add a "traveling to" activity to it. Notice that the line from Portland to Seattle is curved rather than straight, although it doesn't strictly follow a Great Circle line either.continue reading...
Yesterday, Amy was asking if there was a library for drawing curved lines between two points on a map. She wants to use this for her travel posts, which say for example "Tokyo to Boston". We noticed that Facebook draws curved lines when they show a planned trip. Martijn was able to figure out how to reproduce this on Facebook consistently. You have to start by creating a "checkin" post, then add a "traveling to" activity to it. Notice that the line from Portland to Seattle is curved rather than straight, although it doesn't strictly follow a Great Circle line either.continue reading...
