WeChat ID
aaronpk_tv
#microsub
-

My current thought for this is to add a new property to the entry with the source's
h-cardinfo:{ "type": "entry", "url": "https://example.com/1000", ... ... "_source": { "url": https://example.com/", "name": "Example Feed", "photo": "https://example.com/photo.jpg" } }My main question is whether the
urlshould be the home page URL of the feed or the actual feed URL. I'm almost thinking we need to be able to include both.If you're following an Atom/RSS/JSONfeed, then the feed URL is not something you'd want to send a user to, so you'd want the "home page" URL instead. For HTML feeds, it would be fine to use the feed URL directly.
However from a security perspective, if the entry's URL is on a different domain than the URL the entry was found on, the UI may want to indicate this in some way, similar to how my webmentions display the source URL as "via ____" if the source URL domain is different from the entry's reported URL. The main case this might happen is an aggregator where the every item in the feed is from a different domain than the aggregator's feed. Also micro.blog feeds where the post's original URL is reported instead of the micro.blog URL.
So I'm thinking we might need two properties, feed URL and home page URL. Unfortunately this no longer maps well to
h-card. Any ideas? -
store mapping between channels and default micropub destinations
in the channel settings, provide a dropdown to select the default micropub destinationcontinue reading... -
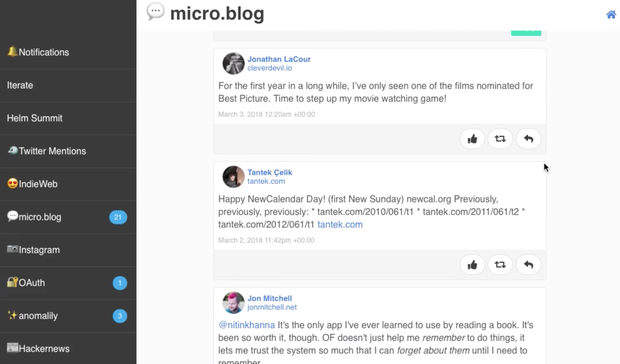
Monocle+Aperture are coming along nicely!
I just got my GitHub notifications piped into the reader, which is a much nicer experience than reading them via email or trying to track them down on github.com!
I have a few channels set to show just an indicator dot when there are new posts rather than showing the number of new posts, a much calmer experience.
Unread posts show up with a faint yellow glow around them, and they're automatically marked as read when they scroll off the screen.
At this point, I've actually moved all of the feeds I was previously following from IRC into Aperture as a way to force myself to continue putting the finishing touches on it!
-
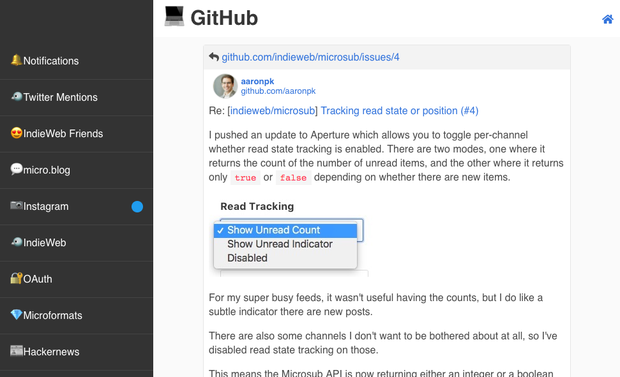
I pushed an update to Aperture which allows you to toggle per-channel whether read state tracking is enabled. There are two modes, one where it returns the count of the number of unread items, and the other where it returns only
trueorfalsedepending on whether there are new items.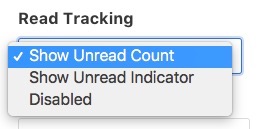
For my super busy feeds, it wasn't useful having the counts, but I do like a subtle indicator there are new posts.
There are also some channels I don't want to be bothered about at all, so I've disabled read state tracking on those.
This means the Microsub API is now returning either an integer or a boolean for the
unreadproperty on channels, e.g.:{ "channels": [ { "uid": "notifications", "name": "Notifications", "unread": 0 }, { "uid": "31eccfe322d6c48c50dea2c84efc74ff", "name": "IndieWeb" "unread": true } ] } -
Can you provide examples of what you're finding that is not normalized?
Microsub is not "merely delivering the content from other locations". Microsub is in fact specifically already doing a lot of normalization of the content it finds, producing a feed that is much more standardized than what it discovered when crawling the feeds, even to the point of making vocabulary-specific decisions about some values.
-
Fun side effect of using https://granary.io and Aperture to follow conference hashtags is I end up with a private archive of all the tweets! #indieweb #microsub
-
Streaming API
Clients should have a way to tap in to some sort of streaming API to get updates from the server in realtime.continue reading... -
I just updated the text to hopefully be more explicit about this: https://indieweb.org/Microsub-spec#Set_Channel_Order
-
No, that's not what I meant.
Only the order of the channel IDs specified will be changed
In your example 1,
chas moved as well, even though onlydandbwere given.To move a channel up or down...
This is equivalent to swapping two adjacent items.
I didn't give an example of setting the order of three items because I couldn't think of a UI where it would make sense, but it is still possible.
The nice thing about this approach is that the same update logic works for all the use cases, and doesn't matter how many items are in the list, and is atomic.
-
The
beforeandaftervalues are meant to represent pages of data, not necessarily individual records. In my case, theaftervalue refers to an item that isn't in the current page. I could return a string for_idthat looks more like thebeforeandafterstrings, but that's just an implementation detail of my server. Alternately I may switch mybefore/afterstrings to look more like the current_idvalue. Either way, this difference doesn't seem important to the client. -
That would be an interesting feature that the microsub server could provide to clients. It does seem like this will always be a problem.
-
Channel icons?
I just added emoji in the channel names, and now I'm wondering if there should be a way to choose/upload an actual custom icon for channels.continue reading... -
Here's a question. Do you imagine this additional state being something that only individual clients are aware of, or should that be synced to the server as well?
If the server returns the "updated" date, then the client has enough information to show the indicator itself. But as far as other clients are concerned, they wouldn't know about whether you've seen those posts in another client.
I'm kind of leaning towards it being a client-only thing, at least for now.
If that's going to end up getting pushed to the server then I think we need to better define the different kinds of states. Maybe "read" vs "seen", where "seen" is the soft indicator that the client has displayed the post to the user, and "read" means they've opened it up (or maybe even explicitly marked it as read). -
Add option to remove entries when unfollowing a source
When removing a source from a channel, Aperture provides an option in the UI to either remove all the existing entries or just stop adding new entries. It may be useful for this to be an option for Microsub clients as well.continue reading... -
I'm implementing a draft of this in Aperture right now. Here is the current API.
Every entry now includes a unique system ID, meant for internal identification of the item (not global identification). This is returned in the timeline response as the parameter
_id, and there is now also_is_read. For example:{ "items": [ { "type": "entry", "url": "http://example.com/100", ... "_id": "41003", "_is_read": false ] }These new
_idvalues are meant to be opaque to clients, and must always be a string. Some servers will likely use integer database IDs, but other servers may use other string identifiers for entries depending on the implementation.Retrieving the list of channels now also includes the number of unread entries in the channel:
{ "channels": [ { "uid": "notifications", "name": "Notifications", "unread": 0 }, { "uid": "YPGiUrZjNM36LNdpFy7eSzJE7o2aK82z", "name": "IndieWeb", "unread": 7 } ] }To mark an individual entry as read:
action=timelinechannel=examplemethod=mark_readentry=1234
To mark multiple entires as read:
action=timelinechannel=examplemethod=mark_readentry[]=1234entry[]=5678
Both of the above also work with
method=mark_unread.To mark an entry read as well as everything before it:
action=timelinechannel=examplemethod=mark_readlast_read_entry=1234
This is to address the use case of streams, where you really only care about knowing where in the stream you've scrolled to and whether there are any new entries since then.
This is mostly inspired by the Feedly Markers API Mark one or more articles as read and Mark a feed as read
-
Here is a diff of the changes.
The main differences can be read here:
-
Okay, it sounds like we have a proposal for some changes around how these channels are handled:
• The only special uid is `notifications`
• A Microsub server is required to start with a single "Home" channel, the uid can be whatever it wants
• Users can remove or rename the initial default channel
• Servers MUST return the `notifications` channel as the first channel in the list
• Servers MUST ignore the `notifications` channel when reordering channels
• Clients SHOULD show the `notifications` channel separately in the UI -
Some silo examples of "home" vs "notifications":
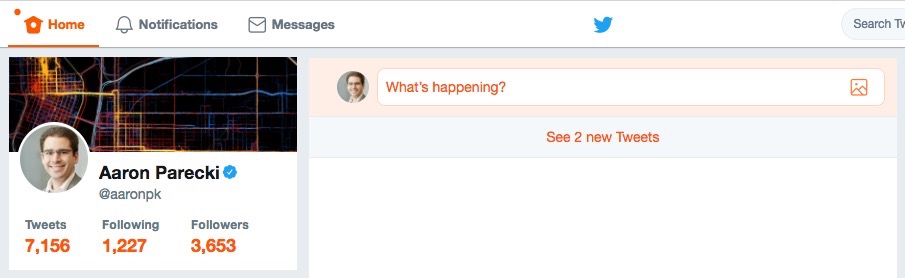

and of course more on the wiki
Some discussion from IRC about whether hardcoding a "home" channel even makes sense in the first place.
