Day 60: Emoji Detector Library for PHP #100DaysOfIndieWeb
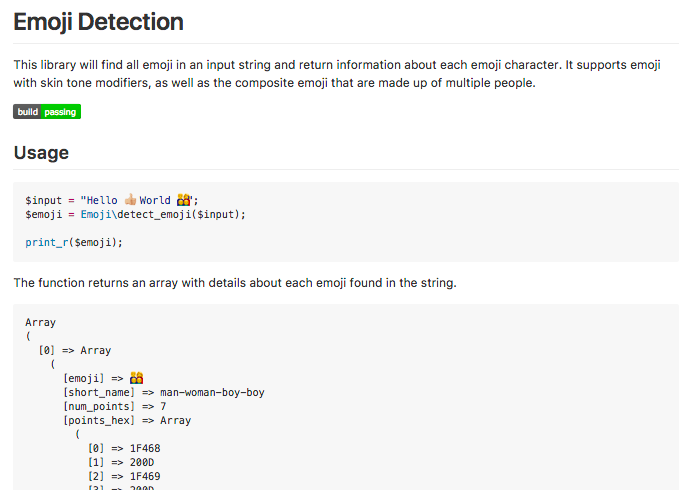
I wanted to find all emoji in a string, including info about them, for my next #100Days project. However I couldn't find a library that does this. The closes I found was iamcal's Emoji conversion library, which can replace emoji in a string with HTML tags, as well as the EmojiOne library which can replace emoji in a string with shortcodes.
continue reading...
