I wanted to find all emoji in a string, including info about them, for my next #100Days project. However I couldn't find a library that does this. The closes I found was iamcal's Emoji conversion library, which can replace emoji in a string with HTML tags, as well as the EmojiOne library which can replace emoji in a string with shortcodes.
I started down a path of attempting to understand unicode encoding. A very helpful resource is this post from 2003 titled "The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)". It's worth a read if you have to deal with user input at all.
If you aren't familiar with the details of Emoji, Unicode and UTF-8 encoding, then what you probably don't realize is that an emoji character such as 👨👩👦👦 is actually composed of seven unicode characters. Each person is a separate character, and they are all connected with the "Zero-Width-Join" (ZWJ) character. This ends up being seven code points in total: 👨 [ZWJ] 👩 [ZWJ] 👦 [ZWJ] 👦. There are also skin tone modifiers which are their own character. So an emoji like 👍🏼 is actually two characters, the 👍 plus the skin-tone-3 modifier.
To further complicate things, I've been talking about unicode code points, but it turns out these code points can be represented in any number of ways in a string depending on the string encoding. Typically we only need to worry about handling UTF-8 encoded strings now, so that's where I started. The UTF-8 encoding of a character like "A" is the same as the ASCII encoding of the character, using only one byte. However a character such as 👍 requires more than one byte to represent. This means actually finding meaningful emoji in a string is not as simple as reading byte by byte, and is not even as simple as reading UTF-8-character by character.
Thankfully, EmojiOne has done the hard work of finding the Emoji characters in a string. However their library doesn't have a way to return the Emoji found, it can only be used to replace them. I also didn't like the list of short names they use, I prefer the Slack names instead.
What I ended up with was putting together the parsing regex from EmojiOne with the Emoji data from Slack's data set. I turned this into a library that returns the data I want to use. Here's how it works.
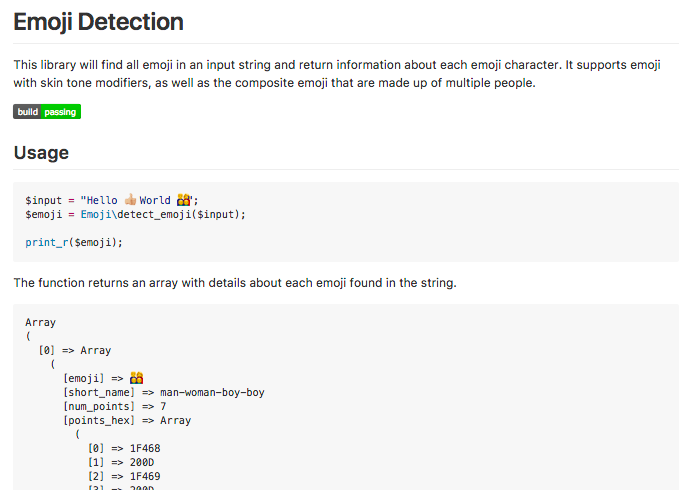
Given an input string that may contain emoji characters, this function will find any emoji in the string and return an array with information about each character.
$input = "Hello 👍🏼 World 👨👩👦👦";
$emoji = Emoji\detect_emoji($input);
emoji- The emoji sequence found, as the original byte sequence. You can output this to show the original emoji.short_name- The short name of the emoji, as defined by Slack's emoji data.num_points- The number of unicode code points that this emoji is composed of.points_hex- An array of each unicode code point that makes up this emoji. These are returned as hex strings. This will also include "invisible" characters such as the ZWJ character and skin tone modifiers.hex_str- A list of all unicode code points in their hex form separated by hyphens. This string is present in the Slack emoji data array.skin_tone- If a skin tone modifier was used in the emoji, this field indicates which skin tone, since theshort_namewill not include the skin tone.
This package is now available on GitHub, and via Composer!
composer require p3k/emoji-detector
🎉👍


👍