In August 2012, I wrote a quick script to stream front-page Hackernews stories to an IRC channel on Freenode (##hackernews in case you're interested) so that I could quickly glance at popular stories there instead of needing to load Hackernews. Since IRC is my feed reader, I've always tried to pipe as much there as possible.
Parsing the Hackernews front page HTML
In 2012 there was no API for Hackernews, so my only option was to use one of the unofficial ones, or read the HTML from the front page myself. I opted to parse the HTML directly since it wasn't super complex. I know you shouldn't parse HTML with a regex, but I did anyway. It worked great, from August 2012 up until April 2015.
Finally this month I stopped seeing updates in the channel, and went to take a look. It appears they made a slight change to the HTML which of course broke my regex, since I was matching against some specific markup. I also learned from someone else in the channel, that Hackernews had launched an official JSON API in October. I decided to rewrite the code to work with that API rather than try to update my regex.
Switching to the JSON API
It took only a few minutes to rewrite the script using two endpoints, topstories.json and fetching an item. However, within two days, I had already encountered a problem. The IRC bot started spitting out empty lines in IRC, one for each front-page story. My code was by no means foolproof, and I realized that this would happen if the API call to fetch story details returned an empty result.
So in 2.5 years of parsing the HTML, I never had any problems. In 2 days of parsing the JSON API, I hit a glitch where all the stories were empty.
2015-04-26 19:43:03 Loqi [hackernews] ( points) https://news.ycombinator.com/item?id= 2015-04-26 19:43:06 Loqi [hackernews] ( points) https://news.ycombinator.com/item?id= 2015-04-26 19:43:08 Loqi [hackernews] ( points) https://news.ycombinator.com/item?id= 2015-04-26 19:43:11 Loqi [hackernews] ( points) https://news.ycombinator.com/item?id= 2015-04-26 19:43:14 Loqi [hackernews] ( points) https://news.ycombinator.com/item?id= 2015-04-26 19:43:17 Loqi [hackernews] ( points) https://news.ycombinator.com/item?id= 2015-04-26 19:43:20 Loqi [hackernews] ( points) https://news.ycombinator.com/item?id=
Make the visible data machine readable
Since more people and programs see the HTML than use the API, the HTML ends up being more reliable. Luckily there's a simple solution to avoid nasty regex parsing hacks in order to be able to generate a machine-readable (and JSON!) version of an HTML page. It requires the author of the HTML to add a few classes to their existing markup. We'll use the Hackernews front page markup as an example.
Here's a snippet of HTML from the current Hackernews front page for a single story.
<tr class="athing">
<td align="right" valign="top" class="title">
<span class="rank">19.</span>
</td>
<td>
<center><a id="up_9443241" onclick="return vote(this)" href="vote?for=9443241&dir=up&auth=4f617c803a44687927291cd133ac825ca9e61c4b&goto=news"><div class="votearrow" title="upvote"></div></a></center>
</td>
<td class="title">
<span class="deadmark"></span>
<a href="http://www.dmiller.io/blog/2015/4/26/comparing-the-php7-and-hack-type-systems">Comparing the PHP 7 and Hack Type Systems</a>
<span class="sitebit comhead"> (dmiller.io)</span>
</td>
</tr>
<tr>
<td colspan="2"></td>
<td class="subtext">
<span class="score" id="score_9443241">40 points</span>
by <a href="user?id=jazzdan">jazzdan</a>
<a href="item?id=9443241">7 hours ago</a>
| <a href="flag?id=9443241&on=t&dir=down&auth=4f617c803a44687927291cd133ac825ca9e61c4b&goto=news">flag</a>
| <a href="item?id=9443241">20 comments</a>
</td>
</tr>
If this looks like a chunk of HTML you don't want to touch with a 10-foot pole, I don't blame you. In order to make this easily machine-readable, without requiring custom parsing of HTML, we can add a few Microformats classes to turn these into h-entry posts.
First, wrap both table rows with a <tbody> tag with a class of h-entry in order to group these rows into a single element. (And yes, it's okay for a table to have multiple tbody tags.)
<tbody class="h-entry"> ... </tbody>
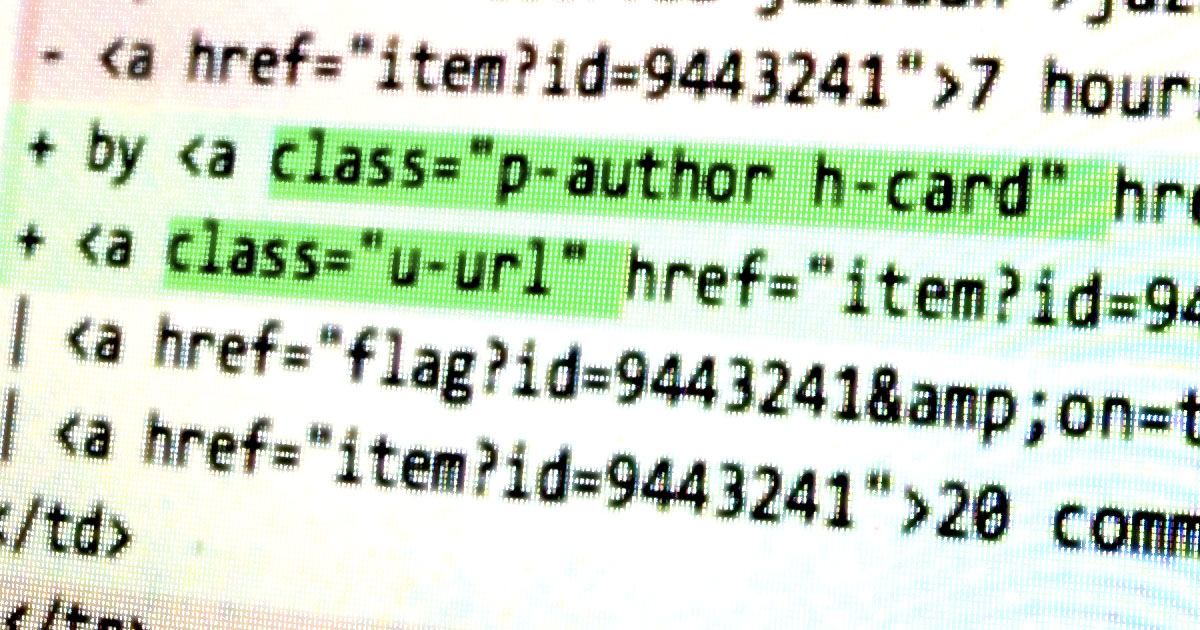
Find the line that contains the permalink to the story as well as the name, and add the u-url and p-name classes:
<a class="u-url p-name" href="http://www.dmiller.io/blog/2015/4/26/comparing-the-php7-and-hack-type-systems">Comparing the PHP 7 and Hack Type Systems</a>
Find the link to the person who submitted the post, and add the p-author class:
by <a class="p-author h-card" href="user?id=jazzdan">jazzdan</a>
Lastly, indicate the time the post was created as well as the post's permalink on news.ycombinator.com:
<a class="u-url" href="item?id=9443241"><time datetime="2015-04-26T14:15:00-0700" class="dt-published">7 hours ago</time></a>
Here's a summary of the changes in colorized diff format. You can see the additions are extremely minor, and didn't involve changing the structure of the HTML with the exception of adding the <tbody> tag.
| @@ -1,3 +1,4 @@ | ||
| +<tbody class="h-entry"> | ||
| <tr class="athing"> | ||
| <td align="right" valign="top" class="title"> | ||
| <span class="rank">19.</span> | ||
| @@ -7,7 +8,7 @@ | ||
| </td> | ||
| <td class="title"> | ||
| <span class="deadmark"></span> | ||
| - <a href="http://www.dmiller.io/blog/2015/4/26/comparing-the-php7-and-hack-type-systems">Comparing the PHP 7 and Hack Type Systems</a> | ||
| + <a class="u-url p-name" href="http://www.dmiller.io/blog/2015/4/26/comparing-the-php7-and-hack-type-systems">Comparing the PHP 7 and Hack Type Systems</a> | ||
| <span class="sitebit comhead"> (dmiller.io)</span> | ||
| </td> | ||
| </tr> | ||
| @@ -15,9 +16,10 @@ | ||
| <td colspan="2"></td> | ||
| <td class="subtext"> | ||
| <span class="score" id="score_9443241">40 points</span> | ||
| - by <a href="user?id=jazzdan">jazzdan</a> | ||
| - <a href="item?id=9443241">7 hours ago</a> | ||
| + by <a class="p-author h-card" href="user?id=jazzdan">jazzdan</a> | ||
| + <a class="u-url" href="item?id=9443241"><time datetime="2015-04-26T14:15:00-0700" class="dt-published">7 hours ago</time></a> | ||
| | <a href="flag?id=9443241&on=t&dir=down&auth=4f617c803a44687927291cd133ac825ca9e61c4b&goto=news">flag</a> | ||
| | <a href="item?id=9443241">20 comments</a> | ||
| </td> | ||
| -</tr> | ||
| +</tr> | ||
| +</tbody> | ||
What does this give us? If you run the new HTML through a microformats parser (online, PHP, Ruby, Python, Node.js), then the result is a data structure representing the item!
{
"items": [
{
"type": [
"h-entry"
],
"properties": {
"author": [
{
"type": [
"h-card"
],
"properties": {
"name": [
"jazzdan"
],
"url": [
"http:\/\/news.ycombinator.com\/user?id=jazzdan"
]
},
"value": "jazzdan"
}
],
"name": [
"Comparing the PHP 7 and Hack Type Systems"
],
"url": [
"http:\/\/www.dmiller.io\/blog\/2015\/4\/26\/comparing-the-php7-and-hack-type-systems",
"http:\/\/news.ycombinator.com\/item?id=9443241"
],
"published": [
"2015-04-26T14:15:00-0700"
]
}
}
]
}
This means consuming code can rely on a Microformats parser to deal with the (potentially messy) HTML, and only needs to handle the well-structured output that you see above.
If Hackernews were to add this markup to the front page, it would give people an easy way to parse the stories. This would enable me to add Hackernews to my IndieWeb reader, as well as give me an easy way to stream the front-page stories to IRC, while not relying on a third-party API.
IndieWebCamp
For more about how we're using Microformats to enable cross-site following, commenting and other interactions, check out the IndieWebCamp wiki!
You might also like to join us for an IndieWebCamp in Düsseldorf, Portland, or Edinburgh!

Could even take it one step further by using HTML as one's API (hat tip to @aaronpk on https://aaronparecki.com/2015/04/26/22/html-is-my-api) to peek at the <source type=> to even filter out particular media types in advance using a whitelist on the client's side.
That could be extended for the <video> and <audio> tags too.