WeChat ID
aaronpk_tv
-
 Chicago, Illinois • Tue, January 7, 2020 5:16pm
Chicago, Illinois • Tue, January 7, 2020 5:16pm

-
at CTA - O'HareChicago, Illinois • Tue, January 7, 2020 4:09pmomg they support Apple Pay now this is great!
-
Portland, Oregon • Tue, January 7, 2020 8:42amLong line this morning
-
Portland, Oregon • Tue, January 7, 2020 8:40amHaven't been here in a while!
-
I haven't packed for a trip in 6 weeks. I wonder if I still remember how.
-
at Doe DonutsPortland, Oregon • Sat, January 4, 2020 6:16pm


-
Portland, Oregon • Tue, December 31, 2019 5:29pm

-
 All I want for my birthday is for you to subscribe to my YouTube channel 😄 Let's hit 1000 today! 🚀
All I want for my birthday is for you to subscribe to my YouTube channel 😄 Let's hit 1000 today! 🚀
https://youtube.com/aaronpk?sub_confirmation=1 -
 This hits a little too close to home in more ways than one 🙈
This hits a little too close to home in more ways than one 🙈
🎥 https://youtu.be/N3p9ez9JmLs
https://twitter.com/davemaze/status/1210696745920819202 -
at IKEAPortland, Oregon • Fri, December 27, 2019 1:42pmFor some reason I'm the only bike parked here
-
 I was in the middle of making a Negroni and ran out of Vermouth, so I subbed Becherovka instead and wow is this a mouthful of flavor! 🍸
I was in the middle of making a Negroni and ran out of Vermouth, so I subbed Becherovka instead and wow is this a mouthful of flavor! 🍸 -
Portland, Oregon • Thu, December 26, 2019 11:35am
-
Business card goals:
"My Business Card Runs Linux"
https://www.thirtythreeforty.net/posts/2019/12/my-business-card-runs-linux/ -
Announcing events.indieweb.org!
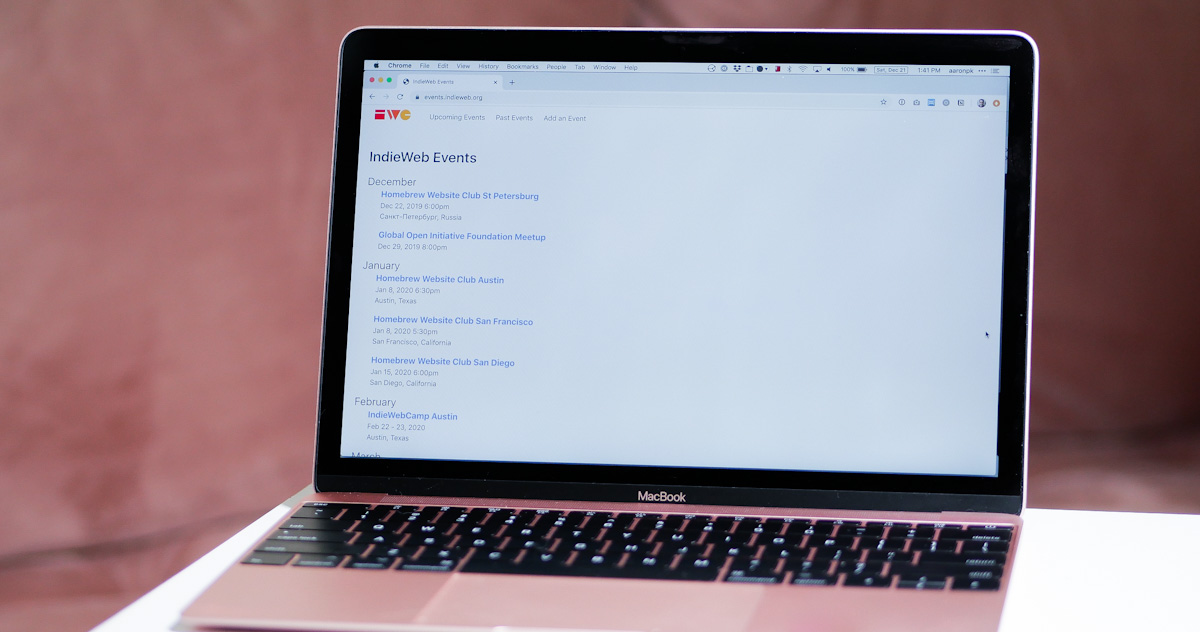 I'm super happy to announce the launch of a new website for IndieWeb events at events.indieweb.org!continue reading...
I'm super happy to announce the launch of a new website for IndieWeb events at events.indieweb.org!continue reading... -
The problem with posting stuff on Craigslist is now it means I have to answer all the unknown numbers that call my phone for the next few days.
-
Some more info on OAuth 2.1 from the @oktadev blog:
OAuth 2.1: How many RFCs does it take to change a light bulb?
https://developer.okta.com/blog/2019/12/13/oauth-2-1-how-many-rfcs -
It's Time for OAuth 2.1
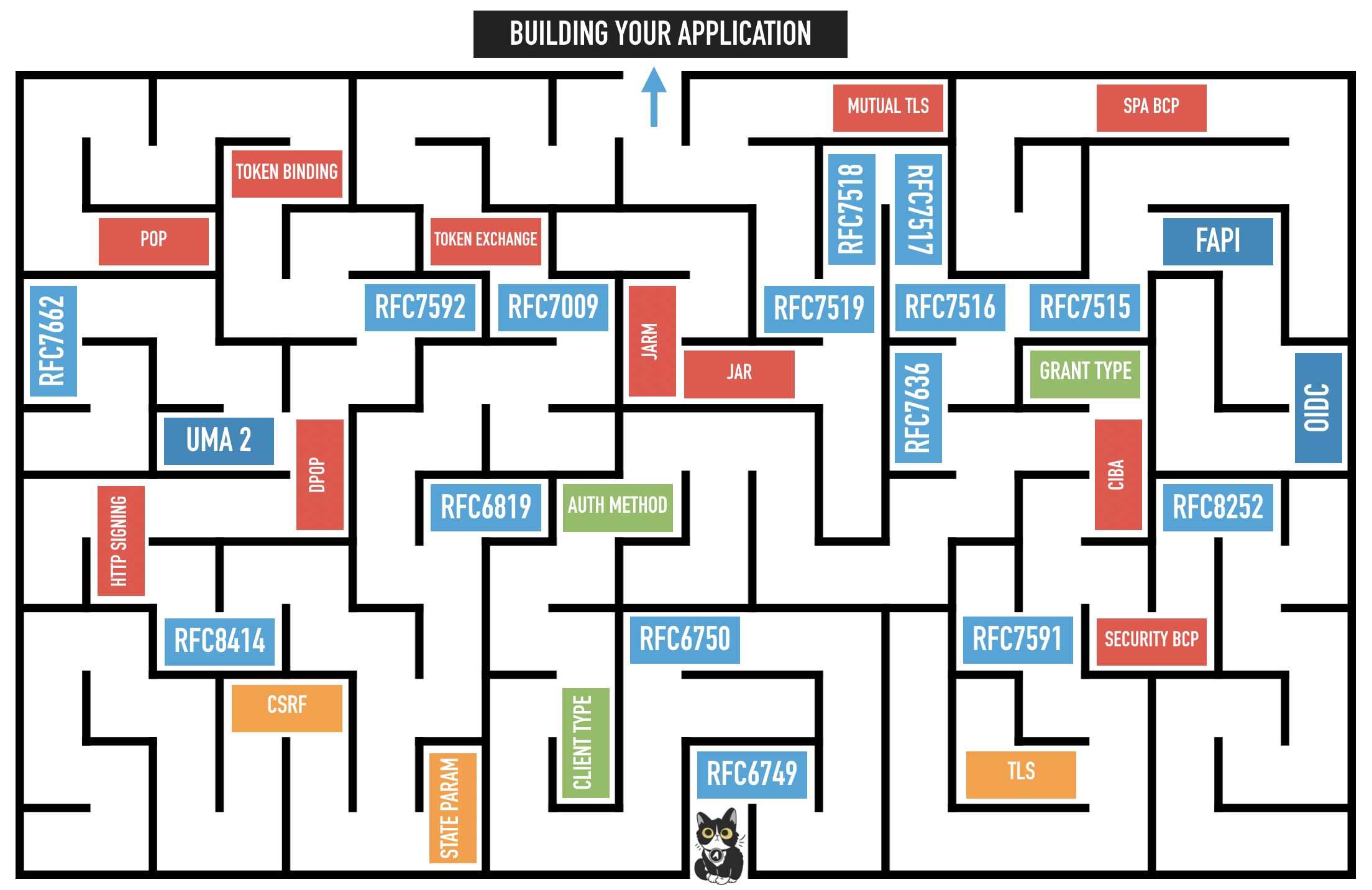 Trying to understand OAuth often feels like being trapped inside a maze of specs, trying to find your way out, before you can finally do what you actually set out to do: build your application.continue reading...
Trying to understand OAuth often feels like being trapped inside a maze of specs, trying to find your way out, before you can finally do what you actually set out to do: build your application.continue reading... -
In a couple hours I'll be going live to talk about using #OAuth to protect your APIs! It's not too late to join!
https://twitter.com/oktadev/status/1205173016407097344 -
aaand office hours are a wrap!
If you're curious how I got this nice greenscreen effect with my cat background without chewing up the CPU on my computer, I made a video that talks about the new @Blackmagic_News ATEM Mini that I used for this!
https://www.youtube.com/watch?v=fx2Iq-_qRz4
