I was sitting at the back of the API discussion at the Quantified Self Conference this Friday in San Francisco, and realized that there is something wrong with the current way these quantified self devices are built and marketed. I don't want to buy a device and be trapped in the company's ecosystem of apps and be stuck in yet another social network. I want to use these physical devices as inputs to my own data store, and have a completely separate set of companies handle the social and aggregation of data from the data that I own.
The Current QS Device Ecosystem
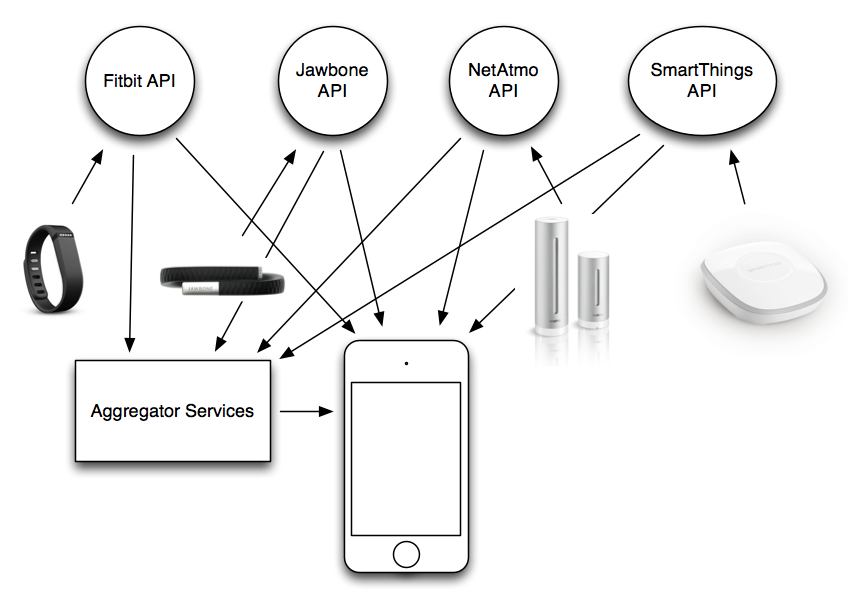
In the current model, every device has its own app and its own social network, and most of them have an API. Each device wants you to completely buy into their entire world. This is even more apparent when you see apps like Jawbone UP and Fitbit letting you track things that their devices don't track, like food and water consumption!
This presents a number of questions and challenges with privacy and data ownership. You have to trust that these services are handling your data properly, letting you share with who you want to share it with, etc. If you request that your account is deleted, you have to trust that they delete it.
Many of these APIs are designed only to support displaying data in the corresponding apps, the API is not necessarily designed to be a complete export of your own data. A common problem is when times come back from the API in the user's local time without even including timezone information. Surprisingly, some of these APIs don't return unix timestamps or full ISO 8601 dates. The problem of course is that without the actual timestamp, you can't correlate this data with anything else.
Of course if the company shuts down, you lose all of the data stored in the system. As we've seen before, like with the Zeo sleep tracker shutting down suddenly without giving any notice, this is a big problem. Even the way a company is acquired can make it beneficial to hide the fact the service will be shut down until after the acquisition, so that the value of the company is not affected by negative press about a service shutting down.
The Ideal QS Device Ecosystem
A better framework is to separate the device manufacturers from the app builders. Let companies like Jawbone and Fitbit focus on building great hardware, and let other companies build social networks and aggregators of the raw data.
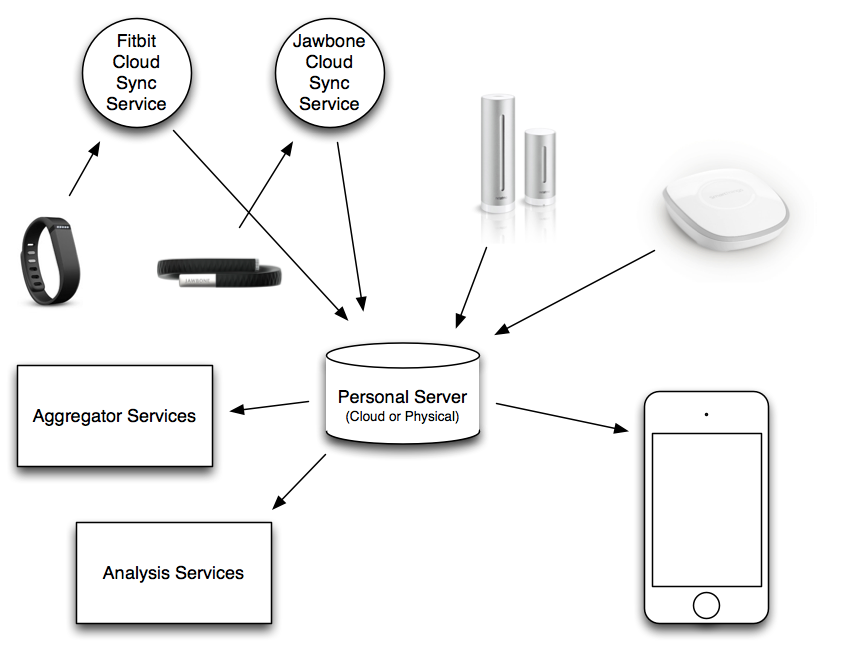
In this model, I would buy or rent a personal server that would collect and house my QS data from all of my devices. This might be a physical device I plug in at home like an Airport Express, or it may be a server I rent from Amazon or Linode, or could even be a service provided by a company dedicated to this purpose. This personal server would be responsible for storing and backing up all of my data. It may or may not actually have a user interface for viewing the data, most importantly it has an API for getting data in and out.
A device manufacturer like Jawbone would build a device that could send data to my personal server. Of course it's not always practical or possible to communicate straight from a wearable device to a server at home (although Bluetooth LE makes this increasingly easier). So in the mean time, it's completely acceptable that a device may require a cloud service operated by the device manufacturer in order to sync and process data. The main difference is that in this model, I'm not treating Jawbone's servers as an API, they are simply a "syncing service" that exists to push data down to my own server. This also simplifies things greatly for Jawbone, since they don't need to worry about building mobile apps or websites, they can focus on building great hardware.
Once I've set up many devices to push data to my personal server, I may want to share some parts of it publicly or with a social network. I may also want to see aggregate graphs of weight data or step counts, or correlate my sleep data with the air quality of my home.
This would all be accomplished by having separate aggregator and separate analysis services. I would selectively grant them access to the data on my personal server using a framework like OAuth 2, where they would be able to pull out the pieces they need.
How do we get there?
Creating this "indie web of things" is hopefully not too far of a stretch given the foundations we're laying with the building blocks of the indie web.
You can start by getting your own domain name and backing up your personal data to your own server. Until this new ecosystem exists, you can get a head start by downloading your data from APIs like Jawbone and Fitbit, and storing it on your personal server.
This post details aspects of the IndieWeb community, a community of people who own their data and their online identity. We're currently focusing on this type of architecture for the web, starting with what we've been calling POSSE, publishing content on your own site and syndicating to sites like Twitter and Facebook.
 Aaron Parecki is known for having tracked his location at 5 second intervals since 2008, tracking many other types of personal data, such as sleep, weight, heart rate, personal weather and air quality. He is a proponent of data ownership, and uses his domain as his own personal data store and indentiy provider. Parecki founded IndieWebCamp with Tantek Çelik and Amber Case in 2010. Previously he was the co-founder of Geoloqi, a location-based software company acquired by Esri in 2012.
Aaron Parecki is known for having tracked his location at 5 second intervals since 2008, tracking many other types of personal data, such as sleep, weight, heart rate, personal weather and air quality. He is a proponent of data ownership, and uses his domain as his own personal data store and indentiy provider. Parecki founded IndieWebCamp with Tantek Çelik and Amber Case in 2010. Previously he was the co-founder of Geoloqi, a location-based software company acquired by Esri in 2012.
Parecki currently works as the CTO of Esri Portland R&D Center. His personal data collections have been featured in Wired, Fast Company and at conferences around the world. You can follow him on Twitter \@aaronpk or on his own domain, aaronparecki.com/notes
